AG电子
首页
定制家居
AG电子厨柜
AG电子衣柜
AG电子木门
阳台卫浴
桔家
AG电子厨电
智小金智能家居
家具软装
AG电子精装
走进AG电子
关于AG电子
全球的AG电子
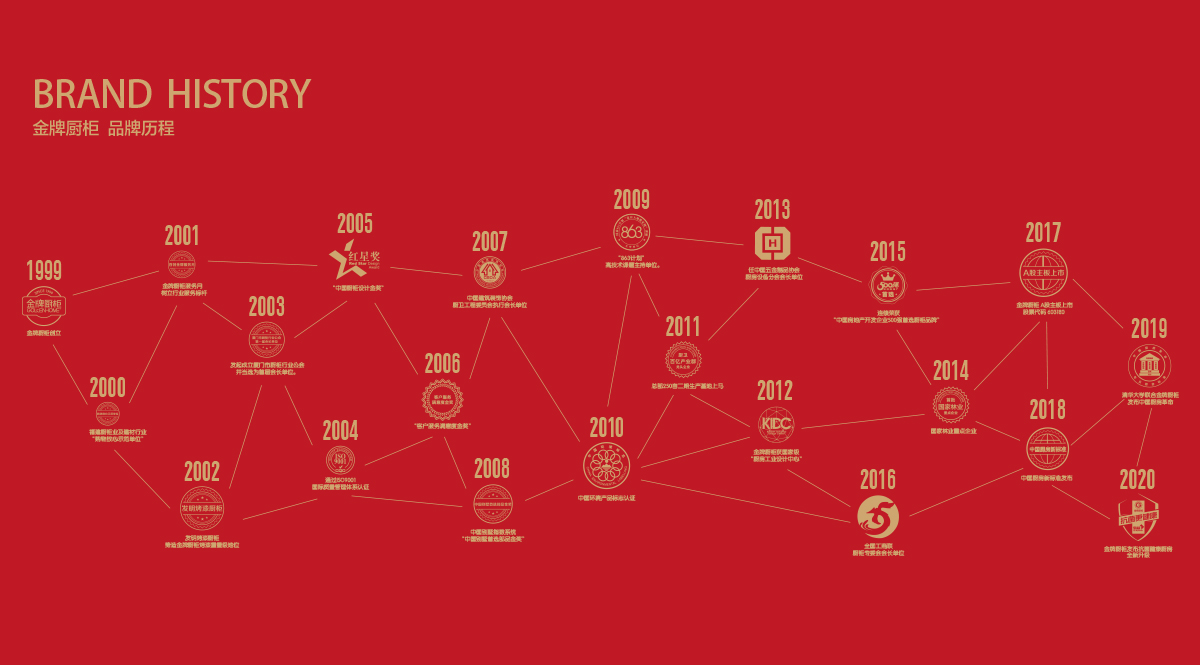
品牌历史
AG电子智能
厨房&家
AG电子服务
全球网点
服务流程
订单查询
AG电子服务季
十年品质保障
常见问题
在线反馈
产品使用说明
资讯中心
品牌资讯
中国爱厨日
投资者关系
公司治理
公司公告
互动交流
加入AG电子
加盟AG电子
AG电子直聘
海外招商
您好 欢迎光临AG电子家居官网!
招商加盟
全国客服热线:400-1868-666
首页
定制家居
AG电子厨柜
AG电子衣柜
AG电子木门
阳台卫浴
桔家
AG电子厨电
智小金智能家居
家具软装
AG电子精装
走进AG电子
关于AG电子
全球的AG电子
品牌历史
AG电子智能
厨房&家
AG电子服务
全球网点
服务流程
订单查询
AG电子服务季
十年品质保障
常见问题
在线反馈
产品使用说明
资讯中心
品牌资讯
中国爱厨日
投资者关系
公司治理
公司公告
互动交流
加入AG电子
加盟AG电子
AG电子直聘
海外招商
定制家居
AG电子厨柜
AG电子衣柜
AG电子木门
AG电子厨电
家具软装
峰絮
查看更多
希格
查看更多
静奢
查看更多
云间
查看更多
峰漫
查看更多
峰絮
查看更多
静奢
查看更多
云间
查看更多
峰漫
查看更多
云珩
查看更多
峰絮
查看更多
门墙一体拼色产品
查看更多
云界
查看更多
木茵
查看更多
柜电一体好厨房
查看更多
木梵品牌整家套餐-餐厅空间
查看更多
木梵品牌整家套餐-卧室空间
查看更多
木梵品牌整家套餐-客厅空间
查看更多
AG电子沙发花系魅影01款
查看更多
走进AG电子
关于AG电子
全球的AG电子
品牌历史
AG电子智能
厨房&家
关于AG电子
查看更多
全球的AG电子
查看更多
品牌历史
查看更多
智小金智慧开关门板
查看更多
厨房&家-让每个人体验回家的美好
查看更多
资讯中心
品牌资讯
中国爱厨日
四喜临门!AG电子家居全域布局驱动泛家居产业发展!
查看更多
云端共擎,定制未来:AG电子家居与厦门航空共绘可持续发展新图景
查看更多
AG电子家居跨界体育营销:以足球为媒,燃动苏超赛场与城市活力!
查看更多
飞流AI家装设计智能体2.1正式上线!多模态交互大跃升,持续引领行业变革!
查看更多
AG电子家居联合新华社客户端“以旧换新 惠民工程”正式启动!
查看更多
中国爱厨日
查看更多
中国爱厨日
查看更多